Mastering SQL Partitioning: A Comprehensive Guide To Multi-Column Partitioning
How can you manage and optimize large SQL tables efficiently? The answer: SQL partitioning by multiple columns.
SQL partitioning by multiple columns is a powerful technique used to enhance the performance and manageability of massive SQL tables. It involves dividing a table into smaller, more manageable chunks based on specific column values, allowing for efficient data retrieval, processing, and maintenance.
The significance of SQL partitioning by multiple columns lies in its ability to improve query performance. By partitioning data based on commonly queried columns, databases can quickly narrow down the search, reducing the amount of data that needs to be scanned. This partitioning strategy also simplifies data management tasks such as data loading, backups, and maintenance, as operations can be performed on specific partitions rather than the entire table.
In the realm of data warehousing and large-scale data processing, SQL partitioning by multiple columns has emerged as an essential technique. It empowers organizations to effectively handle massive datasets, optimize query performance, and streamline data management processes. As the volume of data continues to grow exponentially, the adoption of SQL partitioning techniques will play a critical role in ensuring efficient and scalable data management systems.
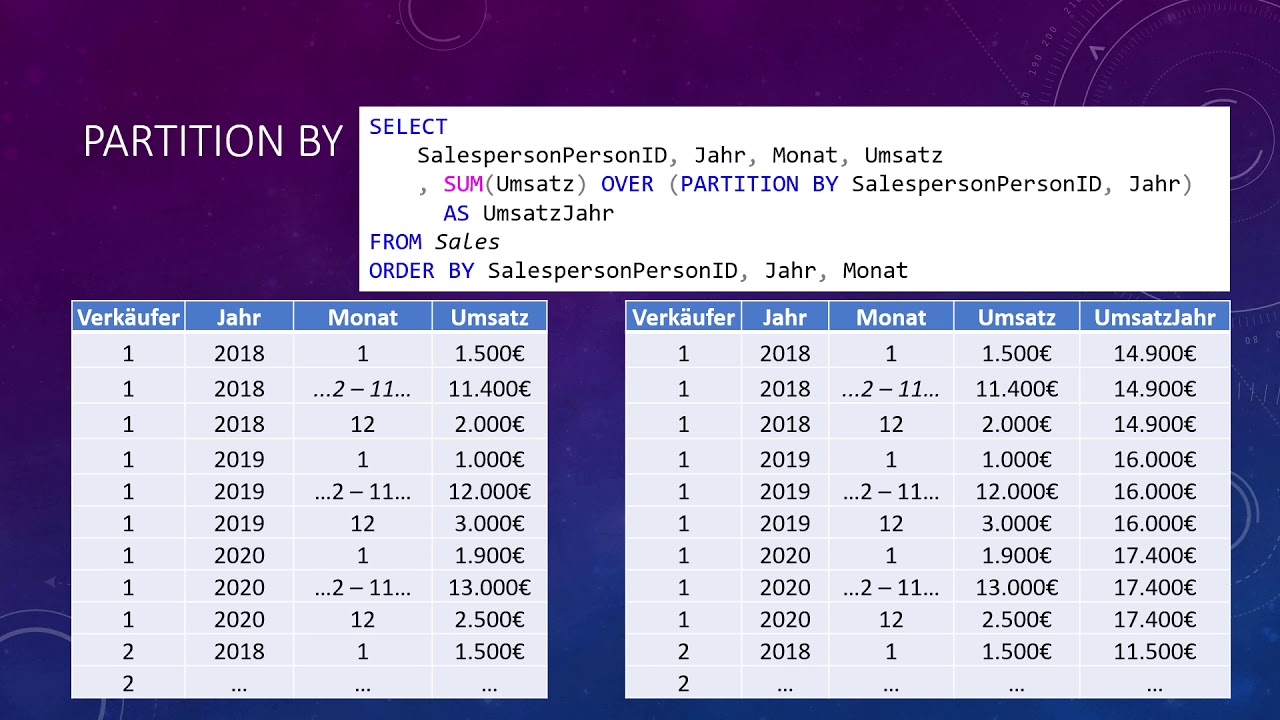
SQL Partitioning by Multiple Columns
SQL partitioning by multiple columns is a powerful technique for managing and optimizing large SQL tables. It involves dividing a table into smaller, more manageable chunks based on specific column values, allowing for efficient data retrieval, processing, and maintenance.
- Performance Optimization: Partitioned tables enable faster query execution by reducing the amount of data that needs to be scanned.
- Data Management Simplification: Partitioning simplifies data management tasks such as data loading, backups, and maintenance, as operations can be performed on specific partitions.
- Scalability: Partitioning allows tables to grow to massive sizes while maintaining performance and manageability.
- Data Distribution: Partitions can be distributed across multiple physical storage devices, improving performance and reducing I/O bottlenecks.
- Query Optimization: Partitioning enables the use of partition pruning techniques, which can significantly improve query performance.
- Data Warehousing: Partitioning is essential for managing large data warehouses, where data is often partitioned by time or subject area.
- Data Analytics: Partitioning facilitates efficient data analysis by allowing analysts to quickly access and process specific subsets of data.
In summary, SQL partitioning by multiple columns is a multifaceted technique that offers significant benefits for managing and optimizing large SQL tables. It improves performance, simplifies data management, enhances scalability, and supports efficient data distribution, query optimization, data warehousing, and data analytics.
Performance Optimization
SQL partitioning by multiple columns plays a pivotal role in performance optimization by leveraging partitioned tables. Partitioned tables are physically divided into smaller, more manageable chunks based on specific column values. This strategic division allows databases to significantly reduce the amount of data that needs to be scanned when executing queries.
Consider a large table containing millions of records. Without partitioning, a query that retrieves data for a specific date range would require scanning the entire table, which can be a time-consuming and resource-intensive process. However, by partitioning the table based on the date column, the database can quickly identify and access only the relevant partition, drastically reducing the amount of data that needs to be processed. This partitioning technique dramatically improves query performance, especially for tables with a large number of records.
The performance benefits of SQL partitioning by multiple columns extend to complex queries involving multiple criteria. By partitioning the table on multiple columns, the database can efficiently narrow down the search space, resulting in even faster query execution times. This optimization is particularly valuable for data warehousing applications, where complex queries are frequently used to analyze large volumes of data.
In summary, the connection between SQL partitioning by multiple columns and performance optimization is evident in the ability of partitioned tables to reduce the amount of data that needs to be scanned during query execution. This reduction in data scanning directly translates to faster query response times, improved system performance, and enhanced overall efficiency, making SQL partitioning an essential technique for managing and optimizing large SQL tables.
Data Management Simplification
The connection between SQL partitioning by multiple columns and data management simplification lies in the ability to perform operations on specific partitions rather than the entire table. This granular approach offers significant advantages, particularly for large tables with millions or even billions of records.
Consider the task of loading data into a large table. Without partitioning, the entire table would need to be locked during the load process, potentially impacting other concurrent operations. However, with partitioned tables, only the affected partition needs to be locked, allowing other operations to proceed without interruption. This optimized approach minimizes downtime and improves overall system performance.
Similarly, backups and maintenance tasks can be simplified and accelerated using SQL partitioning. By backing up or maintaining only specific partitions, organizations can reduce the time and resources required for these operations. This is especially beneficial for large tables where only a subset of data needs to be backed up or maintained.
Furthermore, partitioning enables efficient data purging and archiving. By moving older or inactive data to separate partitions, organizations can optimize storage utilization and improve query performance on active data. This data management strategy is particularly valuable for long-term data retention scenarios.
In summary, SQL partitioning by multiple columns simplifies data management tasks by allowing operations to be performed on specific partitions. This granular approach reduces downtime, improves system performance, and streamlines backups, maintenance, and data purging processes, making it an essential technique for managing large SQL tables.
Scalability
In the realm of data management, scalability is paramount for handling the ever-increasing volume of data generated by modern applications. SQL partitioning by multiple columns plays a pivotal role in achieving scalability by enabling tables to grow to massive sizes without compromising performance or manageability.
- Data Volume Management: Partitioning allows organizations to effectively manage massive datasets by dividing them into smaller, more manageable chunks. This approach simplifies data handling, reduces processing times, and improves overall system performance.
- Elastic Scaling: Partitioned tables can be easily scaled up or down to accommodate changing data volumes. This elasticity ensures that the system can handle fluctuations in data without compromising performance or incurring downtime.
- Improved Concurrency: Partitioning reduces contention and improves concurrency by distributing data across multiple partitions. This enables multiple users to access and modify different partitions concurrently, enhancing overall system throughput.
- Simplified Maintenance: Managing large tables can be challenging and time-consuming. Partitioning simplifies maintenance tasks, such as backups, restores, and data reorganization, by allowing operations to be performed on individual partitions rather than the entire table.
In summary, SQL partitioning by multiple columns is a powerful technique for achieving scalability in data management. By dividing tables into smaller partitions, organizations can effectively handle massive datasets, ensure elastic scaling, improve concurrency, and simplify maintenance tasks, making it an essential strategy for managing and optimizing large SQL tables.
Data Distribution
Data distribution is a crucial aspect of SQL partitioning by multiple columns. By distributing partitions across multiple physical storage devices, organizations can significantly improve performance and reduce I/O bottlenecks, making it a critical component of effective data management.
Consider a scenario where a large table is stored on a single physical storage device. When queries are executed against this table, the storage device becomes a performance bottleneck, limiting the overall throughput of the system. However, by partitioning the table and distributing the partitions across multiple storage devices, the I/O load is balanced, reducing bottlenecks and improving query performance.
Furthermore, data distribution enhances data availability and fault tolerance. In the event of a storage device failure, only the affected partition is impacted, while the remaining data remains accessible. This redundancy ensures that critical data is protected against hardware failures, minimizing data loss and downtime.
In summary, data distribution is an essential component of SQL partitioning by multiple columns. By distributing partitions across multiple physical storage devices, organizations can improve performance, reduce I/O bottlenecks, and enhance data availability and fault tolerance. This understanding is crucial for designing and implementing scalable and efficient data management systems.
Query Optimization
Partition pruning is a powerful technique that significantly enhances query performance in SQL databases. It involves identifying and eliminating partitions that do not contain any data relevant to the query being executed. This optimization technique is made possible by partitioning the table by multiple columns, which allows the database to determine which partitions are relevant based on the specified query criteria.
To illustrate the connection between SQL partitioning by multiple columns and query optimization, consider the following example. Suppose you have a large table containing millions of customer records, and you want to retrieve all customers who made a purchase in a specific date range. Without partitioning, the database would need to scan the entire table to find the relevant records, which could be a time-consuming process.
However, by partitioning the table by the date column, the database can quickly identify the partitions that contain data for the specified date range. The database can then skip scanning the partitions that do not contain any relevant data, resulting in a significant reduction in query execution time. This optimized approach is particularly beneficial for tables with a large number of records and complex queries involving multiple criteria.
In summary, SQL partitioning by multiple columns plays a critical role in query optimization by enabling the use of partition pruning techniques. By dividing the table into smaller, more manageable partitions, the database can quickly identify and eliminate irrelevant partitions, leading to faster query execution times and improved overall system performance.
Data Warehousing
In the realm of big data and data warehousing, SQL partitioning by multiple columns plays a pivotal role in managing and optimizing massive datasets. Data warehouses often store vast amounts of historical and transactional data, which can be effectively partitioned to enhance performance, simplify management, and improve scalability.
- Performance Optimization
Partitioning data warehouses by time or subject area allows for faster query execution. By narrowing down the search space to specific partitions, databases can significantly reduce the amount of data that needs to be scanned, resulting in improved query response times and overall system performance.
- Data Management Simplification
Managing large data warehouses can be a complex task. Partitioning simplifies data management by enabling administrators to perform operations on specific partitions rather than the entire dataset. This granular approach streamlines tasks such as data loading, backups, and maintenance, reducing downtime and improving overall efficiency.
- Scalability and Concurrency
As data warehouses grow in size, partitioning becomes essential for scalability. By distributing data across multiple partitions, organizations can handle massive datasets without compromising performance or encountering concurrency issues. This scalability ensures that data warehouses can accommodate increasing data volumes while maintaining optimal performance.
- Data Analysis and Reporting
Partitioning data warehouses by subject area or time enables efficient data analysis and reporting. Analysts can quickly access and analyze specific subsets of data, allowing for more targeted and insightful reporting. This optimized approach supports faster decision-making and improves the overall effectiveness of data analysis.
In summary, the connection between "Data Warehousing: Partitioning is essential for managing large data warehouses, where data is often partitioned by time or subject area." and "sql partition by multiple columns" lies in the ability of partitioning to enhance performance, simplify management, ensure scalability, and facilitate efficient data analysis and reporting in large data warehouse environments.
Data Analytics
In the realm of data analytics, SQL partitioning by multiple columns plays a crucial role in empowering analysts to efficiently explore and analyze large datasets. Partitioning enables the division of data into smaller, more manageable chunks based on specific criteria, allowing for faster and more targeted data retrieval and processing.
- Improved Query Performance
Partitioning significantly enhances query performance by reducing the amount of data that needs to be scanned. By partitioning data based on commonly queried columns, analysts can quickly narrow down the search space, resulting in faster query execution times and improved overall system performance.
- Granular Data Access
Partitioning provides granular access to specific subsets of data, allowing analysts to focus their analysis on relevant sections of the dataset. This granular approach simplifies data exploration and enables analysts to drill down into specific areas of interest without having to process the entire dataset.
- Enhanced Data Exploration
Partitioning facilitates efficient data exploration by enabling analysts to quickly identify patterns, trends, and outliers within specific partitions. This targeted exploration empowers analysts to gain deeper insights into the data and make more informed decisions.
- Scalable Data Analysis
As data volumes continue to grow, partitioning becomes essential for scalable data analysis. By distributing data across multiple partitions, organizations can handle massive datasets and perform complex analysis without encountering performance bottlenecks or scalability issues.
In summary, the connection between "Data Analytics: Partitioning facilitates efficient data analysis by allowing analysts to quickly access and process specific subsets of data." and "sql partition by multiple columns" lies in the ability of partitioning to enhance query performance, provide granular data access, facilitate efficient data exploration, and support scalable data analysis. By leveraging the power of SQL partitioning, analysts can unlock deeper insights from complex datasets, enabling data-driven decision-making and supporting better business outcomes.
Frequently Asked Questions about SQL Partitioning by Multiple Columns
This section addresses commonly asked questions and misconceptions regarding SQL partitioning by multiple columns.
Question 1: What are the primary benefits of using SQL partitioning by multiple columns?
Answer: SQL partitioning by multiple columns offers numerous advantages, including improved query performance, simplified data management, enhanced scalability, efficient data distribution, optimized query optimization, and support for data warehousing and analytics.
Question 2: How does partitioning improve query performance?
Answer: By dividing tables into smaller partitions based on specific column values, databases can reduce the amount of data that needs to be scanned when executing queries. This targeted approach significantly improves query response times and overall system performance.
Question 3: How does partitioning simplify data management?
Answer: Partitioning enables data management tasks, such as data loading, backups, and maintenance, to be performed on specific partitions rather than the entire table. This granular approach reduces downtime, improves system performance, and streamlines data management processes.
Question 4: What are the scalability benefits of partitioning?
Answer: Partitioning allows tables to grow to massive sizes without compromising performance or manageability. By distributing data across multiple partitions, organizations can effectively handle large datasets, ensure elastic scaling, improve concurrency, and simplify maintenance tasks.
Question 5: How does partitioning contribute to data distribution?
Answer: Partitions can be distributed across multiple physical storage devices, reducing I/O bottlenecks and improving performance. This data distribution enhances data availability, fault tolerance, and supports efficient data processing.
Question 6: What is the role of partitioning in data warehousing and analytics?
Answer: Partitioning is essential for managing large data warehouses, where data is often partitioned by time or subject area. It also facilitates efficient data analysis by allowing analysts to quickly access and process specific subsets of data, leading to faster insights and better decision-making.
In summary, SQL partitioning by multiple columns is a powerful technique that offers a range of benefits for managing, optimizing, and analyzing large SQL tables. Its versatile applications and significant performance enhancements make it a valuable tool for data professionals.
Now that we have explored the basics and benefits of SQL partitioning by multiple columns, let's delve into a more advanced discussion on its implementation and best practices.
Conclusion
In conclusion, SQL partitioning by multiple columns has emerged as a powerful technique for managing, optimizing, and analyzing large SQL tables. By dividing tables into smaller, more manageable partitions based on specific column values, organizations can significantly improve query performance, simplify data management, and enhance scalability.
Partitioning plays a pivotal role in various data management scenarios, including data warehousing, data analytics, and large-scale data processing. Its ability to distribute data across multiple physical storage devices ensures efficient data distribution and fault tolerance. Moreover, partitioning enables the use of partition pruning techniques, further optimizing query execution times.
As the volume of data continues to grow exponentially, SQL partitioning by multiple columns will undoubtedly remain an essential technique for data professionals. Its versatile applications and significant performance enhancements make it a valuable tool for handling massive datasets, extracting meaningful insights, and supporting data-driven decision-making.
The Return Type Of Switch To Method In C# For Window Handles
The Mysterious Death: What Happened To Bobby Bernstein?
The Ultimate Guide To Posman Import: Importing Collections And Environments With Ease





{kind=link}